Enhancing Real-Time Processing of YOLOv5-L Using Pruning Techniques in PyNetsPresso

Hyungjun Lee
Research Engineer, Nota AI
Artificial neural networks are known for their remarkable performance, but they often require high-end computing resources to be applied effectively in real-life situations. Recently, there is a growing need for more lightweight neural networks that can be used in everyday situations.
To address this need, Nota AI has introduced NetsPresso in a form of a user-friendly library designed to accelerate artificial neural networks with just a few lines of code. This post will show you how to use PyNetsPresso [link] to speed up YOLOv5-L to real-time levels. We will also evaluate its performance to provide a comprehensive understanding of its capabilities.

Figure 1: Achieving real-time FPS with minimal performance degradation using PyNetsPresso.
The process of creating a lightweight YOLOv5 model is as follows:
Train a YOLOv5-L model using the YOLOv5 repository provided by NetsPresso. You can find it here: [link].
Generate a lightweight model by employing PyNetsPresso.
Retrain the lightweight model utilizing the repository from step 1. For more comprehensive instructions, please refer to the following repository: [link].
We have conducted preliminary experiments using the VOC dataset, and the latency was calculated based on an average of 100 measurements after the post-conversion to TensorRT on Jetson Xavier.

Figure 2-1: Pruning ratio and latency graph. Latency measured on Jetson Xavier.
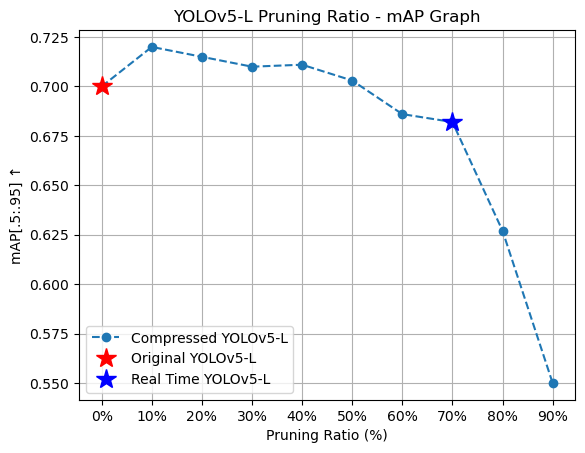
Figure 2-2: Pruning ratio and mAP graph.

Figure 2 -3:Latency and mAP graph. Latency measured on Jetson Xavier.
Summary Table: YOLOv5-L Experimental Results Generated in This Article

It's important to grasp how PyNetsPresso can aid in building lightweight artificial neural networks before we get into the practical implementation. The key lies in a process called Dependency Aware Pruning (DAP). This technique stands in stark contrast to Conventional Pruning methods, which often overlook the interconnected nature of neural networks during the pruning process. By considering the interdependencies within the network, DAP removes parameters strategically, thereby leading to genuine acceleration in performance. On the other hand, Conventional Pruning methods, due to their disregard for these network interdependencies, frequently fall short in achieving similar performance enhancements.
Comparing Latency: Conventional Pruning versus Dependency Aware Pruning

Conventional Pruning
During the process of pruning an artificial neural network, a commonly used technique is to assign a value of zero to the less significant parameters [1, 2]. Unfortunately, this approach is not effective in reducing the size or latency of the network. Even though the parameters are set to zero, they still remain in the network, which means that the network is not truly optimized for efficiency or compactness.

Figure 3: Conventional pruning methods make it impossible to achieve acceleration since parameters cannot be completely eliminated.
Dependency Aware Pruning
In contrast to Conventional Pruning methods, the DAP provided by PyNetsPresso offers a more effective solution. With DAP, you can keep track of the dependencies between different layers in an artificial neural network and remove unnecessary parameters. This helps reduce latency and size, making the network more efficient and optimized.

Figure 4: Dependency Aware Pruning creates a lightweight artificial neural network by completely removing parameters, taking into account the input/output relationships between each layer.
The DAP feature in PyNetsPresso is highly versatile and not limited to simple network structures. It can handle complex operations within neural networks like Skip-Connection, Concat, and Split functions. This flexibility enables optimization of various artificial neural network architectures.

Figure 5: The operation of Dependency Aware Pruning in Skip-Connections allows for the actual acceleration of artificial neural networks by tracking and eliminating dependencies.
Let's get started with a practical exercise. Before we begin, make sure you have the following three prerequisites:
Your YOLOv5-L model should be trained using the repository mentioned earlier.
You'll need an active account to access PyNetsPresso.
The PyNetsPresso library should be installed on your local system.
We have trained our YOLOv5-L model with the VOC dataset. To create an account, visit py.netspresso.ai. Finally, you can install the PyNetsPresso library by following these steps:

Once you're prepared, import the necessary modules to use PyNetsPresso.

To create a lightweight model with NetsPresso, follow these two steps.
First, create a compressor for the compression process and upload the trained artificial neural network. This will generate a unique 'model.model_id' that you can use to access the uploaded model multiple times.
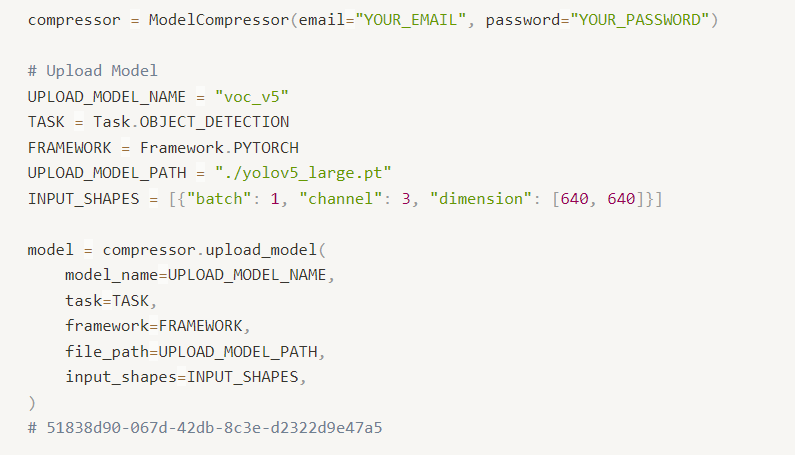
In the second step, you need to set and apply the Recommedation Pruning Ratio for each layer of the artificial neural network to match the target pruning ratio. The method used for setting the Recommended Pruning Ratio is SLAMP [4], a modification of LAMP [3] that is suitable for NetsPresso. After the pruning process, the pruned artificial neural network is stored at the specified 'output_path'.


Figure 6: Results saved in the output_path.
After the completion of all script executions, if you wish to further reduce the weight of the previously uploaded artificial neural network, you can access the uploaded model using 'model_id' as depicted below and continue with pruning in a similar fashion.

The stored artificial neural network needs to undergo retraining to regain its optimum performance. Nota AI has created a solution for this need in the form of a modified repository, based on the official YOLOv5 repository. This repository functions identically to the existing YOLOv5, making all operations seamless and straightforward. More information can be found via the link [link]. The code for the retraining process is as follows.

By doing so, you can obtain a lightweight artificial neural network that's ready for experimentation and practical use in various scenarios.
We have utilized PyNetsPresso's pruning technique to enhance the performance of YOLOv5-L by 2.63 times while experiencing only a 2% reduction in performance. PyNetsPresso provides pruning and neural network acceleration through filter decomposition. To learn more about PyNetsPresso and its applications in accelerating neural networks, real-world scenarios, and creating lightweight neural networks, visit our page.
