EdgeFusion: On-device Text-to-Image Generation

Tairen Piao
Research Engineer, Nota AI
Introduction
The computationally intensive nature of Stable Diffusion (SD) for text-to-image generation hinders its practical deployment. Recent works address this by reducing sampling steps, as in the Latent Consistency Model (LCM), and applying architectural optimizations like pruning and knowledge distillation. We propose EdgeFusion, which diverges by starting with the compact BK-SDM SD variant. We find that directly applying LCM to BK-SDM with commonly used web-crawled datasets yields unsatisfactory results. To overcome this, we develop two key strategies: (1) leveraging high-quality synthetic image-text pairs from leading generative models and (2) designing an advanced distillation process tailored for LCM. Beside, we apply model level tiling and quantization, for on-device deployment, our EdgeFusion model enables rapid generation of photorealistic, text-aligned images in just two denoising steps, with sub-second latency on resource-limited edge devices like NPUs. Fig. 1 shows the overall performance of EdgeFusion.
This paper has been accepted for the CVPR 2024 Workshop on Efficient and On-Device Generation (EDGE)

Figure 1. T2I generation results. When trained with improved data, our EdgeFusion can produce high-quality images from challenging prompts in just a few denoising steps
Key Messages of the Paper
EdgeFusion leverages high-quality image-text pairs from leading generative models to improve compact SD model performance.
EdgeFusion has an advanced distillation process tailored for LCM to enable high-quality few-step inference.
Through model-level tiling and quantization, EdgeFusion achieves one-second photorealistic image generation on Samsung Exynos NPU.
Significance/Importance of the Paper
This work tackles the practical deployment of SD models in resource-constrained environments (e.g., NPUs) by proposing a comprehensive optimization strategy. It addresses the unique computational limitations and memory constraints of NPUs, providing new insights for efficient text-to-image generation on edge devices.
Summary of Methodology
Advanced distillation for LCM
EdgeFusion starts with compressed U-Net design of BK-SDM-Tiny and uses Realistic Vision V5.1 as an advanced teacher model to obtain an improved student called BK-SDM-Adv-Tiny via knowledge distillation.
Instead of distilling from the original Stable Diffusion, the more advanced Realistic Vision V5.1 model is used as the teacher to obtain a better initialized student called BK-SDM-Adv-Tiny.
BK-SDM-Adv-Tiny is fine-tuned using the Latent Consistency Model (LCM) scheduler, but notably, distillation is performed from the original large teacher model instead of a student-like model.

Figure 2. A compact SD with step reduction. (a) Vanilla application of LCM: we initialize BK-LCM-Tiny with the weight from BK-SDM-Tiny and train with distillation to reduce sampling steps. (b) Our approach: improving the initialization of the LCM’s student with a better teacher is beneficial. Moreover, in the LCM training phase, employing the original teacher enhances performance. Leveraging high-quality data is crucial in both phases.
Improved data quality
We recognize limitations in the LAION dataset like low-quality images and irrelevant captions, which can impede training text-to-image models. To address this, we introduce the following methods:
Data preprocessing: Deduplicating data, removing small images, and optimizing image cropping. Through improving quality, it reduced dataset size by 44%.
Synthetic caption generation: Using an LLM (Sphinx) to generate detailed, relevant captions for the preprocessed images to improve text-image correspondence.
Fully synthetic data generation: We generate high-quality synthetic image-text pairs using GPT-4 for prompts and SDXL for image synthesis. This allows control over attributes like demographics for a more diverse, unbiased dataset.
Manual data curation: We further curate 29.9k synthetic samples by correcting prompts and removing artifact images for improved quality.
Deployment on NPU
We apply model-level tiling (MLT) to divide the model into smaller segments to fit within the NPU's memory constraints while reducing DRAM accesses. We also apply kernel fusion and other graph optimizations for efficient execution on the Samsung Exynos NPU.
We perform W8A16 mixed-precision quantization in the U-Net module, FP16 elsewhere, to reduce the model size and accelerate the inference speed.
Experimental Results
Main results
Tab. 1 shows that despite being fine-tuned with just 29.9k samples (synt-cur), BK-SDM-Adv-Tiny outperforms BK-SDM-Tiny by 5.28 (+17.4%) IS and 0.021 CLIP scores. The lower FID score is likely due to the synthetic data distribution differing from COCO and Realistic Vision v5.1 having a worse FID than SD-v1.4. However, our human evaluation (Tab. 2) showing a strong preference for BK-SDM-Adv-Tiny (60.2% win rate) suggests that while comparing to COCO is common practice, assuming COCO as the ideal data distribution may not align well with human preference. Our final model, EdgeFusion, LCM-distilled from BK-SDM-Adv-Tiny on 182.2k samples (L-pps & synt), has close performance to BK-SDM-Tiny and even outperforms it on CLIP (Tabs. 1).

Table 1. Results of the BK-SDM-Tiny architecture trained on different datasets. Evaluated on COCO dataset with 25 steps.
Impact of fine-tuning the student first.
Removing BK-SDM-Tiny finetuning from our advanced distillation pipeline results in a decrease in performance, with −2.67 IS, +2.72 FID and −0.01 CLIP. Again, this observation is confirmed by our human evaluation (Tab. 2), with 61.7% win rate for EdgeFusion.

Table 2. Human preference evaluation. The win rate of our models against the same architecture without improved data and without student finetuning is reported (1500 comparisons, 21 participants).
Quantization
We compare the performance between FP32 and W8A16 quantized EdgeFusion. Fig. 3 shows the results of 3 prompts. There is no performance degradation after applying the W8A16 quantization.

Figure 3. Comparison between FP32 and W8A16 quantized EdgeFusion (2 steps)
NPU benchmark
Tab. 3 shows the relative time ratio results for the cross attention block, without and with the MLT method. The results demonstrate a latency gain of approximately 73% when using MLT, effectively reducing Direct Memory Access (DMA) accesses. Tab. 4 shows the inference efficiency of architectural elements in EdgeFusion.
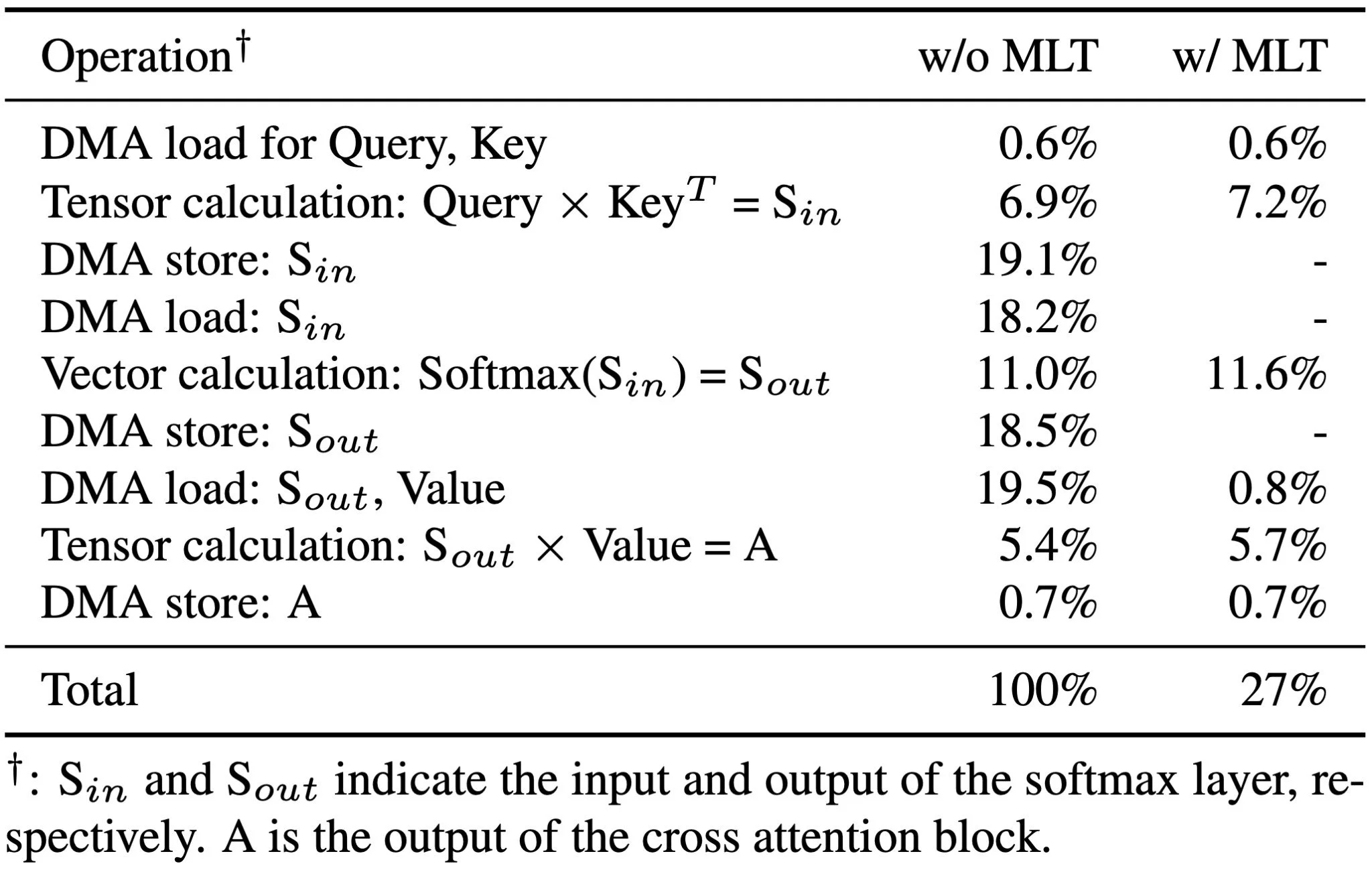
Table 3. Inference time reduction using MLT. For the cross at- tention block, the relative time ratio is computed by comparing operations without MLT to those with MLT.

Table 4. Benchmark on Exynos 2400 with and without MLT.
Conclusion
We propose EdgeFusion to optimize SD models for efficient execution on resource-limited devices. Our findings show that utilizing informative synthetic image-text pairs is crucial for improving the performance of compact SD models. We also design an advanced distillation process for LCM to enable high-quality few-step inference. Through detailed exploration of deployment techniques, EdgeFusion can produce photorealistic images from prompts in one second on Samsung Exynos NPU.
If you have any further inquiries about this research, please feel free to reach out to us at following email address: 📧 contact@nota.ai.
Furthermore, if you have an interest in AI optimization technologies, you can visit our website at 🔗 netspresso.ai.