Deploying an Efficient Vision-Language Model on Mobile Devices

Jaeyeon Kim
Research Engineer, Nota AI

Geonmin Kim
Research Engineer, Nota AI

Hancheol Park
Team Lead of NetsPresso Application, Nota AI
Introduction
Recent large language models (LLMs) have demonstrated unprecedented performance in a variety of natural language processing (NLP) tasks. Thanks to their versatile language processing capabilities, it has become possible to develop various NLP applications that can be beneficially used in real-life scenarios. However, since LLMs require a substantial amount of computational power, ordinary users have to rely on high-performance cloud services to utilize them. In cloud environments, users inevitably face financial burdens. Additionally, there is a risk of exposing personal sensitive data to external parties. Due to these issues, there is a growing demand for using language models on personal laptops or mobile devices.
In response to this demand, smaller LLMs (sLLMs) such as Gemma-2B [1], Phi-3-mini [2], and Llama3-7B [3] have been proposed. Alongside these models, various LLM optimization techniques and deployment tools have been released to enable LLMs to run on laptops and mobile devices. Now, through these open-source resources, sLLMs can successfully operate on mobile devices. Furthermore, there has been a recent increase in the use of vision-language models (VLMs), which attach an image encoder to LLMs to utilize information from images. Naturally, the demand for using VLMs on mobile devices is also growing. However, VLMs require more computational resources because they include a vision transformer (ViT)-based image encoder.
In this article, we describe how we reconstructed one of the VLM models, LLaVA [1], into a lighter model and deployed it on a mobile device. Specifically, we performed lightweight modeling on the LLaVA-v1.5-7B model and modified the MLC LLM [5] used for deployment on mobile devices. Our experimental results showed that our improved LLaVA model achieved an 87% improvement in latency during the image encoding process (37 sec./image -> 6 sec./image). Additionally, we achieved approximately a 50% improvement in decoding speed in the language model (12 tokens/sec.-> 18 tokens/sec.). Despite this significant improvement in latency, there was little to no performance degradation across all benchmarks except for one OCR-related benchmark.
Deploying an Efficient VLM
In this work, we used LLaVA-v.1.5-7B as a baseline model. This model utilizes CLIP ViT-L/14 [6] as its vision model and Vicuna-v1.5-7B as its language model [7]. Although this VLM is relatively small among various VLMs, it is still too large for use in mobile environments. In mobile environments, models smaller than 5B, such as sLLMs, are typically used, necessitating a change in the language model. As an alternative to the language model used in LLaVA, we considered Phi-3-mini (3.8B), which has demonstrated the highest accuracy in various benchmarks among various sLLMs.
Previously, the image encoder used in LLaVA was CLIP ViT-L/14, which divides input images of 336x336 into 14x14 patches, generating 576 tokens plus one image token. Each token is processed through the image encoder and output as a 1,024-dimensional embedding. These embeddings are then transcribed through the projector into the input of the language model. To reduce the model size, we switched the image encoder to CLIP ViT-B/16. CLIP ViT-B/16 divides input images of 224x224 into 16x16 patches, generating a total of 197 token embeddings, each with a dimension of 768, which is smaller than those of CLIP ViT-L/14.
To enable the language model Phi-3 to understand the outputs of the vision model, we trained the projector using the training code and data provided in the official LLaVA repository [11]. To improve the new model's ability to understand and respond to various tasks instructed by the users, we performed visual instruction tuning using LoRA [9], keeping the image encoder frozen.

We named the newly trained model "Phi with Vision Assistant" (PhiVA). For deploying PhiVA in mobile environments, we utilized MLC LLM, known for its effective utilization of device resources among open-source runtimes. Although MLC LLM currently supports the deployment of various LLMs in mobile environments, it does not officially support VLMs yet. For instance, it does not provide modules for processing image and text inputs simultaneously in chat applications or methods for handling image embeddings. We resolved this issue by adapting existing code for image processing from the MLC-Imp [10] repository to fit MLC LLM. In summary, we have developed MLC-VLM-template, which is a system that allows users to plug-and-play different LLMs and vision encoders, port them to mobile, and chat with them. This template is available at https://github.com/nota-github/MLC-VLM-template.

Evaluation
We evaluated the performance of PhiVA on one of the flagship mobile devices, the Galaxy 24 Ultra.
Latency
For LLaVA, the average time to encode one image was 37 seconds, while PhiVA took approximately 6 seconds on average. The decoding process of the language model improved from 12 tokens/sec in the original LLaVA to 18 tokens/sec.

2. Accuracy
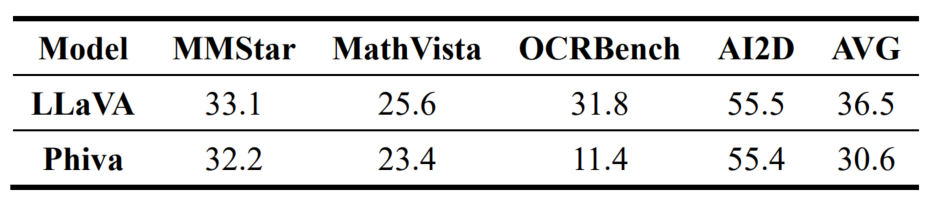
We evaluated our model using VLMEvalKit [1], a standard evaluation method widely used for VLMs. This evaluation method is also used by the OpenVLM Leaderboard [12]. The results showed that PhiVA did not exhibit significant performance degradation on benchmarks, except for OCRBench, which is related to OCR.
Conclusion
In this article, we have described how we optimized the VLM model for deployment on mobile devices. As the first step towards optimization, we utilized pre-developed small models. However, there are various methods for optimization that can be employed. In the future, we plan to explore different optimization techniques to improve latency while minimizing performance degradation. Additionally, there was a significant performance drop in OCR-related benchmarks, which is presumed to be due to the use of efficient training techniques such as LoRA. Future research will investigate the extent of performance recovery for each benchmark based on the training methods used. Finally, we intend to make available the various optimized VLMs generated during this process.
References
[1] Gemma Team. 2024. Gemma: Open Models Based on Gemini Research and Technology. arXiv preprint arXiv:2403.08295.
[2] Microsoft. 2024. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv preprint arXiv:2404.14219.
[3] Meta Llama 3. https://github.com/meta-llama/llama3
[4] Liu et al. 2023. Visual Instruction Tuning. In Proc. NeurIPS 2023.
[5] MLC LLM. https://github.com/mlc-ai/mlc-llm.
[6] Radford et al. 2021. Learning Transferable Visual Models From Natural Language Supervision. arXiv preprint arXiv:2103.00020.
[7] Chiang et al. 2023. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. https://lmsys.org/blog/2023-03-30-vicuna/.
[8] LLaVa. https://github.com/haotian-liu/LLaVA.
[9] Hu et al. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In Proc. ICLR 2022.
[10] MLC-Imp. https://github.com/MILVLG/mlc-imp.
[11] VLMEvalKit. https://github.com/open-compass/VLMEvalKit.
[12] OpenVLM Leaderboard.
https://huggingface.co/spaces/opencompass/open_vlm_leaderboard.
If you have any further inquiries about this research, please feel free to reach out to us at following email address: 📧 contact@nota.ai.
Furthermore, if you have an interest in AI optimization technologies, you can visit our website at 🔗 netspresso.ai.